Update : 2018-05-06
I have found that the website structure of Indeed, Monster, Dice, Careerbuilder have been changed since I wrote these posts. So, some of my code may not work now. But, I think the concept and the process is still the same.
The Github repository for this project : choux130/webscraping_example.
The process of finding jobs online can definitely be a torture. Every day is started by sitting in front of computer, browsing different kind of job searching websites and trying to track every job I have read and then categorizing them into interested or not interested. The whole process is mostly about clicking on different pages and websites, copying and pasting words. At first, you may have enough patience to read and track about 50 or more jobs a day, but when time gets long, you start to feel depressed and feel like yourself is just like a robot. If you have this same kind of experience, you are welcom to check out this post and see how I use automated web scraping techniques in Python 3.6.0 to make my job searching process easier, more efficient and much more fun!
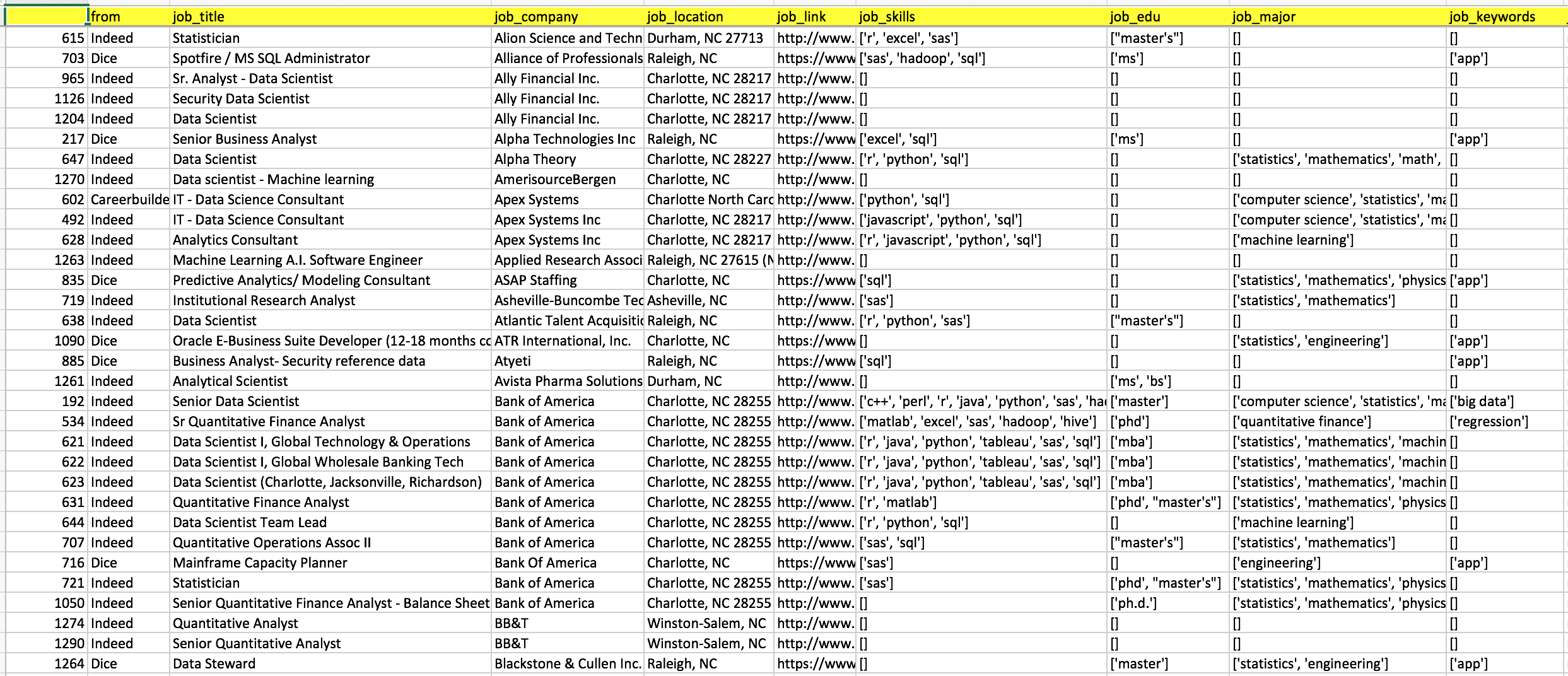
This is just a quick look for one of my final output which was automatically generated by running the Python code. The good thing for this sheet is that I can have a big overview for all the job searching results with their required skills, education level, major and self-interested key words. So, I can easily prioritize the jobs and only focus on ones I think I can be a good fit. Compared to clicking all the job link one by one on all the job searching websites, it really not only saves me a lot of time for the first screening but also make me healthier in mental which to me is the most important thing! If you also think this sheet can be a good idea for your job searching process, please keep reading and grab anything worthy to you.
If you are not a Python 3.6.0 user or only know little about it, don’t worry! Before I did this project, I also know nothing about Python and I just learned by doing. You can find all the example code in my Github repo - webscraping_example. My code may not be the most perfect but it works well on me.
Details
- References
Thank you all so much! - Goals
- Automatically generate a sheet that can include today’s all searching results from 4 different job searching websites (Indeed, Monster, Dice, Careerbuilder).
- For each job result, I would like to know the following things:
- From which Job Searching Website
- Job ID (related to Job Link)
- Job Title
- Job Company
- Location
- Job Link
- Job Type
- Required Skills
- Required Education Level
- Preferred Majors
- Interesting Keywords
- All the Text in the Page
- Steps
For all the following steps, I will use web scraping Careerbuilder as an example. If you are interested in how to do it on other job searching websites ( Indeed, Monster and Dice), please check out my Github repo - webscraping_example.
Example searching criteria:- job searching website: Careerbuilder
- searching keywords: Data Scientist
- city: Durham
- state: NC
Know the URL of the webpage you are going to scrape and know how they related to your searching criteria.
The URL for our example, http://www.careerbuilder.com/jobs-data-scientist-in-durham,nc.######################################################## #################### IMPORT LIBRARY #################### ######################################################## import bs4 import numpy import pandas import re import requests import datetime import stop_words ################################################### #################### ARGUMENTS #################### ################################################### input_job = "data scientist" input_quote = False # add "" on your searching keywords input_city = "Durham" input_state = "NC" sign = "-" BASE_URL_careerbuilder = 'http://www.careerbuilder.com' ##################################################### ##### Function for Transform searching keywords ##### ##################################################### # The default "quote = False" def transform(input,sign, quote = False): syntax = input.replace(" ", sign) if quote == True: syntax = ''.join(['%2522', syntax, '%2522']) return(syntax) ###################################### ########## Generate the URL ########## ###################################### if not input_city: # if (input_city is "") url_dice_list = [ BASE_URL_dice, '/jobs?q=', transform(input_job, sign , input_quote), '+&l=', input_state ] url_dice = ''.join(url_dice_list) else: # input_city is not "" url_dice_list = [ BASE_URL_dice, '/jobs?q=', transform(input_job, sign , input_quote), '&l=', transform(input_city, sign), '%2C+', input_state ] url_dice = ''.join(url_dice_list) print(url_dice)https://www.dice.com/jobs?q=Data+Scientist&l=Durham%2C+NCScrape general contents from the webpage.
To catch the important info from the webpage, we have to start from its HTML code. For the chrome, click right mouse button and choose Inspect. And for the Safari, do the same thing but choose Inspect Element. Then now, we can see all the HTML code for the webpage.Total Number of the results
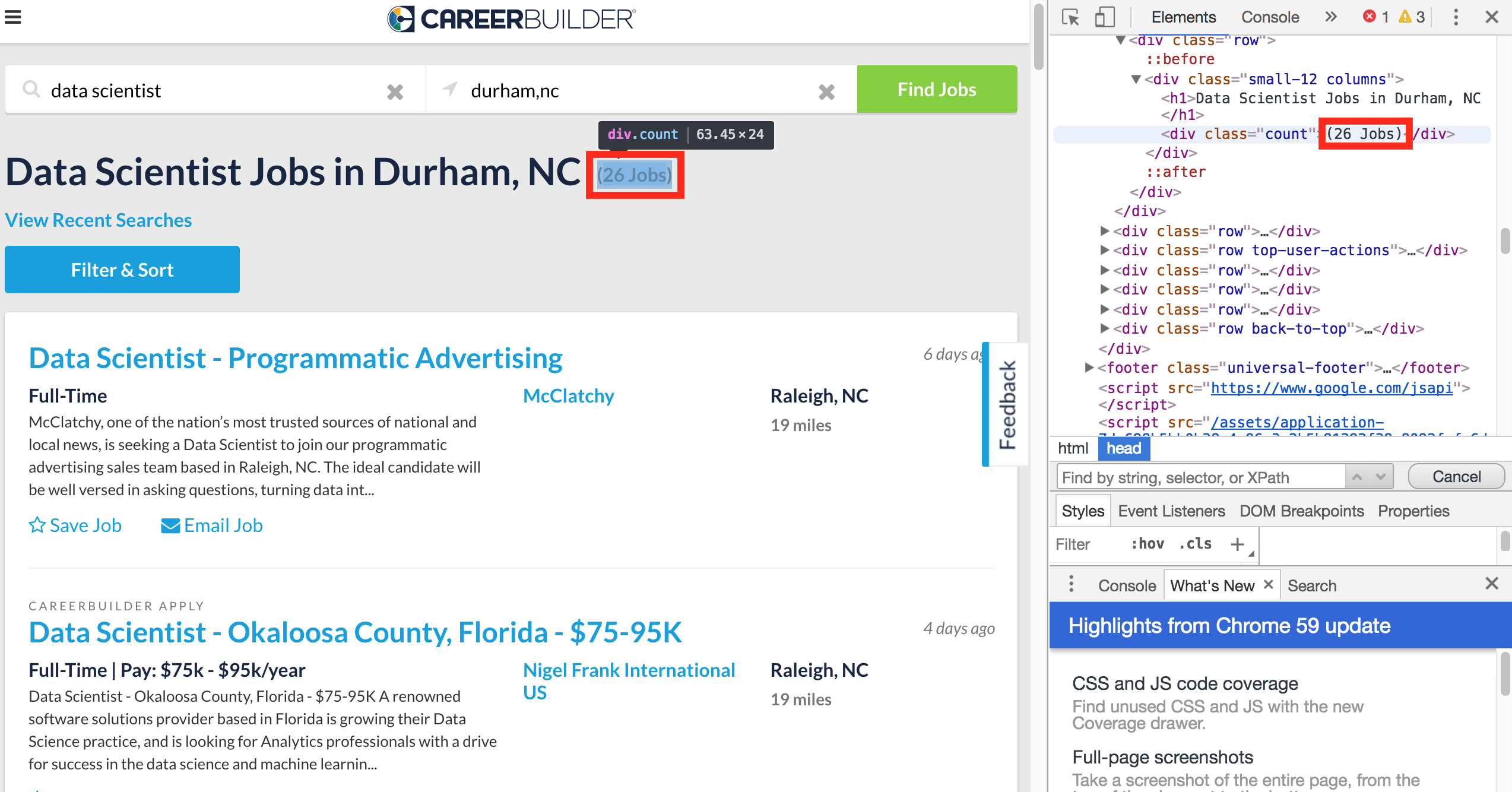
# get the HTML code from the URL rawcode_careerbuilder = requests.get(url_careerbuilder) # Choose "lxml" as parser soup_careerbuilder = bs4.BeautifulSoup(rawcode_careerbuilder.text, "lxml") # total number of results num_total_careerbuilder = soup_careerbuilder.find('div', {'class' : 'count'}).contents[0] print(num_total_careerbuilder) num_total_careerbuilder = int(re.sub('[\(\)\{\}<>]', '', num_total_careerbuilder).split()[0]) print(num_total_careerbuilder)(26 Jobs) 26Total Number of pages
By doing some test and observation, I know that there are 25 positions in one page. Then, I can calculate the total number of pages.# total number of pages num_pages_careerbuilder = int(numpy.ceil(num_total_careerbuilder/25.0)) print(num_pages_careerbuilder)2
Scrape all positions with their basic info for each page.
The basic info for each position is in its
<div class="job-row">...</div>chunk. So, in our code, the first steps would be picking out all the<div class="job-row">...</div>chunks.

For each chunk (or each position), we have following basic features.
- Job Title, Job ID and Job Link
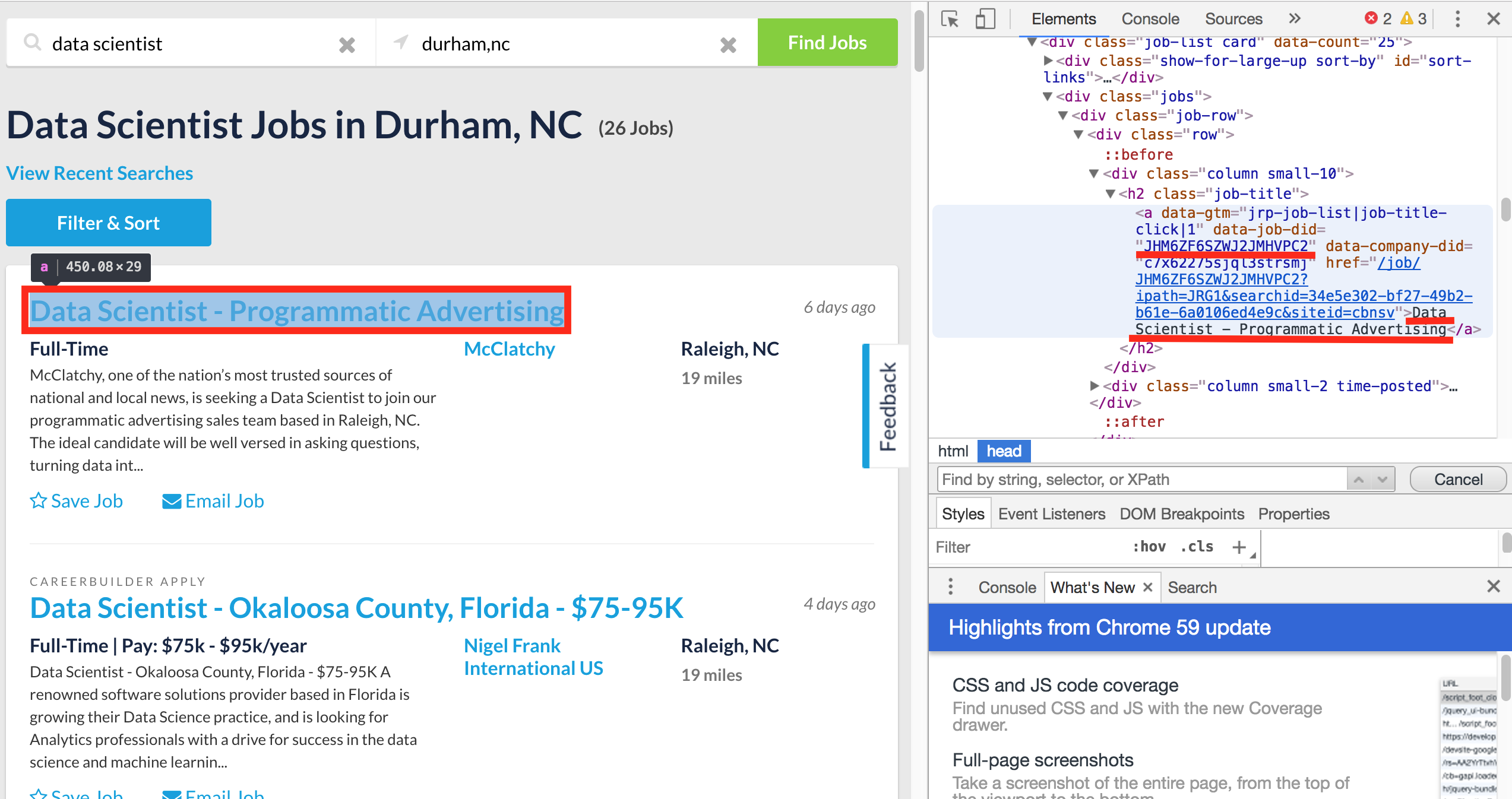
- Job Company
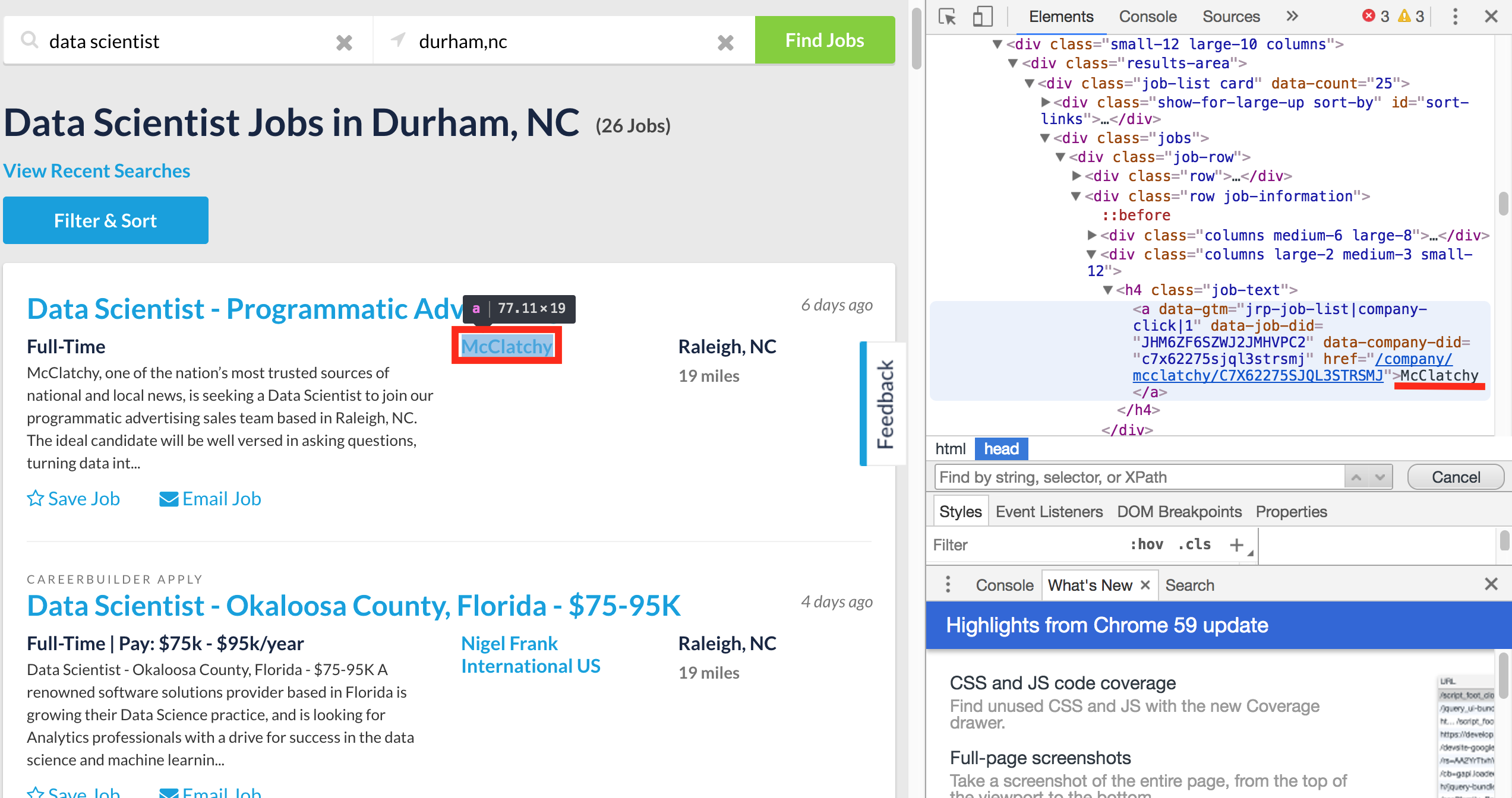
- Location

- Job Title, Job ID and Job Link
The code for picking out all the basic info for each job.
# create an empty dataframe job_df_careerbuilder = pandas.DataFrame() # the date for today now = datetime.datetime.now() now_str = now.strftime("%m/%d/%Y") now_str_name=now.strftime('%m%d%Y') ######################################## ##### Loop for all the total pages ##### ######################################## for i in range(1, num_pages_careerbuilder+1): # generate the URL url = ''.join([url_careerbuilder,'?page_number=', str(i)]) print(url) # get the HTML code from the URL rawcode = requests.get(url) soup = bs4.BeautifulSoup(rawcode.text, "lxml") # pick out all the "div" with "class="job-row" divs = soup.findAll("div") job_divs = [jp for jp in divs if not jp.get('class') is None and 'job-row' in jp.get('class')] # loop for each div chunk for job in job_divs: try: # job id id = job.find('h2',{'class' : 'job-title'}).find('a').attrs['data-job-did'] # job link related to job id link = BASE_URL_careerbuilder + '/job/' + id # job title title = job.find('h2', {'class' : 'job-title'}).text.strip() # job company company = job.find('div', {'class' : 'columns large-2 medium-3 small-12'}).find('h4', {'class': 'job-text'}).text.strip() # job location location = job.find('div', {'class' : 'columns end large-2 medium-3 small-12'}).find('h4', {'class': 'job-text'}).text.strip() except: continue job_df_careerbuilder = job_df_careerbuilder.append({'job_title': title, 'job_id': id, 'job_company': company, 'date': now_str, 'from':'Careerbuilder', 'job_location':location, 'job_link':link},ignore_index=True)http://www.careerbuilder.com/jobs-Data-Scientist-in-Durham,NC?page_number=1 http://www.careerbuilder.com/jobs-Data-Scientist-in-Durham,NC?page_number=2Save the dataframe
# reorder the columns of dataframe cols=['from','date','job_id','job_title','job_company','job_location','job_link'] job_df_careerbuilder = job_df_careerbuilder[cols] # delete the duplicated jobs using job link job_df_careerbuilder = job_df_careerbuilder.drop_duplicates(['job_link'], keep='first') # print the dimenstion of the dataframe print(job_df_careerbuilder.shape) # save the data frame as a csv file path = '/path/output/' + 'job_careerbuilder_' + now_str_name + '.csv' job_df_careerbuilder.to_csv(path)</span></code></pre>(26, 7)
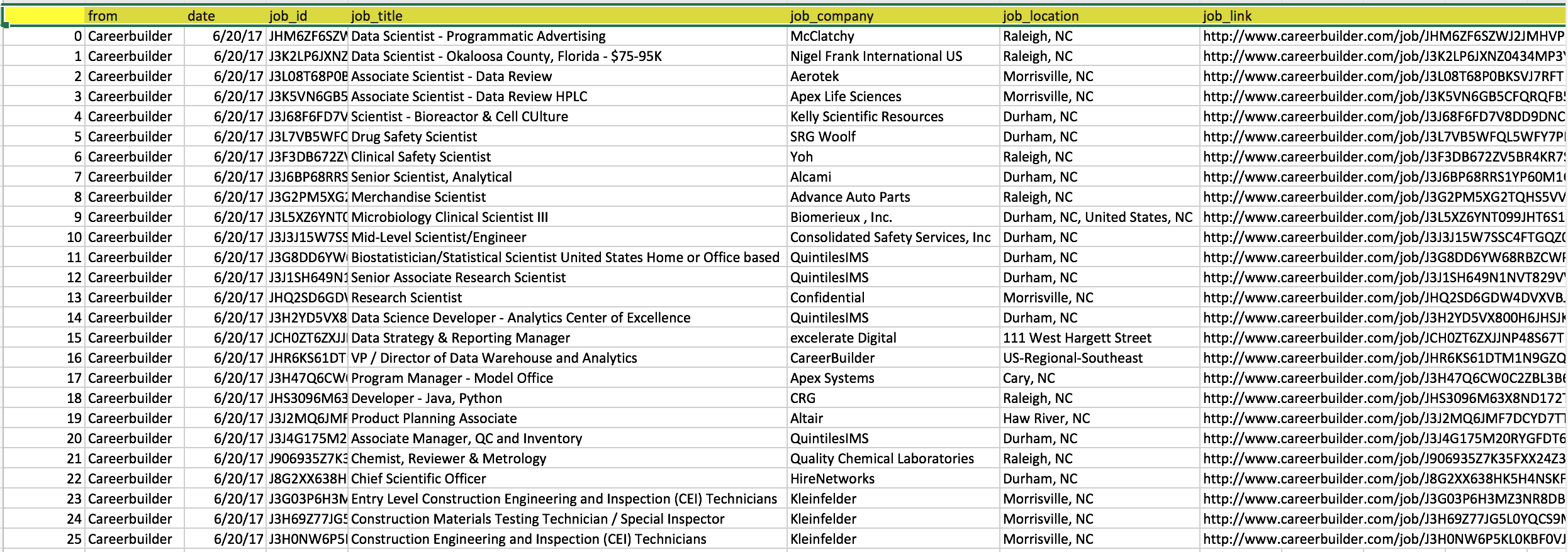
- Only Part I is done! Don’t miss Part II!
Yes, the data frame we have now is not complete yet. Now, we only list out all the searching results in a nice.csvbut this is not enough for helping us efficiently find jobs. So, for the next post I will talk about how to scrape all the URLs in our.csvfile and then to see if they have any contents or words we are interested in. This is the next post, How Web Scraping eases my job searching pain? - Part II : Scrape contents from a list of URLs. Again, all the example python code can be found in my Github repo - webscraping_example.