Update : 2018-05-06
I have found that the website structure of Indeed, Monster, Dice, Careerbuilder have been changed since I wrote these posts. So, some of my code may not work now. But, I think the concept and the process is still the same.
The Github repository for this project : choux130/webscraping_example.
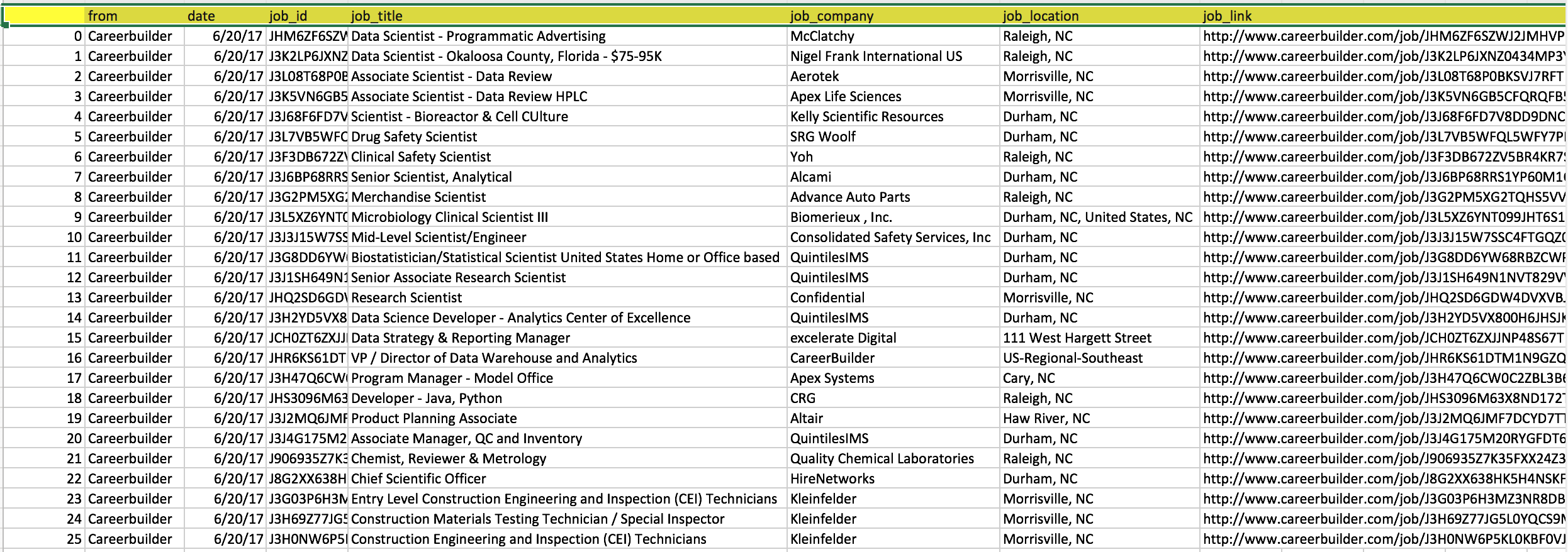
From the previous post, How Web Scraping eases my job searching pain? - Part I : Scrape contents from one URL, we know how to summarize all the job searching results from Careerbuilder into a .csv file with the following features:
- From which Job Searching Website
- Job ID (related to Job Link)
- Job Title
- Job Company
- Location
- Job Link
And, to abtain more details more each job, in this post we are going to add few more features by scraping every Job Link. Hence, for each Job, we will also know their
- Job Type
- Required Skills
- Required Education Level
- Preferred Majors
- Interesting Keywords
- All the Text in the Page

Here is a rough idea about how what we are going to do. First, we have to define what are the Job Type, Required Skills, Required Education Level, Preferred Majors and Interesting Keywords. These can be based on observations on many job description or personal interest. Then, use code to find out whether the defined terms are included in the job pages. If it is in the pages, pick it up and record it in the .csv file.
Details
- References
Thank you all so much! - Steps
Read the
.csvfile saved from Part I and do some preparations.######################################################## #################### IMPORT LIBRARY #################### ######################################################## # import bs4 # import numpy # import pandas # import re # import requests # import datetime # import stop_words # read the csv file # path = '/path/output/' + 'job_careerbuilder_' + now_str_name + '.csv' job_df_careerbuilder = pandas.DataFrame.from_csv(path) # define the stop_words for future use stop_words = stop_words.get_stop_words('english') # list out all the English stop word # print(stop_words)Define what are Job Type, Required Skills, Required Education Level, Preferred Majors, Interesting Keywords and All the Text in the Page.
Job Type
The firsttype_lowerare the exact wording showing in the pages (when searching all the words will be in lower cases). It will be mapped to the updatedtypeby using dictionary, and then be shown in the cell of the.csvfile. The purpose for the mapping is mainly for wording consistency which is important to my future text analysis project, the similarity between all jobs using Term Frequency and Inverse Document Frequency (TF - IDF).#################################################### ##### DEFINE THE TERMS THAT I AM INTERESTED IN ##### #################################################### ##### Job types ##### type = ['Full-Time', 'Full Time', 'Part-Time', 'Part Time', 'Contract', 'Contractor'] type_lower = [s.lower() for s in type] # lowercases, the exact wording # map the type_lower to type type_map = pandas.DataFrame({'raw':type, 'lower':type_lower}) # create a dataframe type_map['raw'] = ["Full-Time", "Full-Time", 'Part-Time', 'Part-Time', "Contract", 'Contract'] # modify the mapping type_dic = list(type_map.set_index('lower').to_dict().values()).pop() # use the dataframe to create a dictionary #print(type_dic){'full-time': 'Full-Time', 'full time': 'Full-Time', 'part-time': 'Part-Time', 'part time': 'Part-Time', 'contract': 'Contract', 'contractor': 'Contract'}Required Skills
It is also referred to Web Scraping Indeed for Key Data Science Job Skills.##### Skills ##### skills = ['R', 'Shiny', 'RStudio', 'Markdown', 'Latex', 'SparkR', 'D3', 'D3.js', 'Unix', 'Linux', 'MySQL', 'Microsoft SQL server', 'SQL', 'Python', 'SPSS', 'SAS', 'C++', 'C', 'C#','Matlab','Java', 'JavaScript', 'HTML', 'HTML5', 'CSS', 'CSS3','PHP', 'Excel', 'Tableau', 'AWS', 'Amazon Web Services ','Google Cloud Platform', 'GCP', 'Microsoft Azure', 'Azure', 'Hadoop', 'Pig', 'Spark', 'ZooKeeper', 'MapReduce', 'Map Reduce','Shark', 'Hive','Oozie', 'Flume', 'HBase', 'Cassandra', 'NoSQL', 'MongoDB', 'GIS', 'Haskell', 'Scala', 'Ruby','Perl', 'Mahout', 'Stata'] skills_lower = [s.lower() for s in skills]# lowercases skills_map = pandas.DataFrame({'raw':skills, 'lower':skills_lower})# create a dataframe skills_map['raw'] = ['R', 'Shiny', 'RStudio', 'Markdown', 'Latex', 'SparkR', 'D3', 'D3', 'Unix', 'Linux', 'MySQL', 'Microsoft SQL server', 'SQL', 'Python', 'SPSS', 'SAS', 'C++', 'C', 'C#','Matlab','Java', 'JavaScript', 'HTML', 'HTML', 'CSS', 'CSS','PHP', 'Excel', 'Tableau', 'AWS', 'AWS','GCP', 'GCP', 'Azure', 'Azure', 'Hadoop', 'Pig', 'Spark', 'ZooKeeper', 'MapReduce', 'MapReduce','Shark', 'Hive','Oozie', 'Flume', 'HBase', 'Cassandra', 'NoSQL', 'MongoDB', 'GIS', 'Haskell', 'Scala', 'Ruby','Perl', 'Mahout', 'Stata'] skills_dic = list(skills_map.set_index('lower').to_dict().values()).pop()# use the dataframe to create a dictionary # print(skills_dic)Required Education Level
##### Education ##### edu = ['Bachelor', "Bachelor's", 'BS', 'B.S', 'B.S.', 'Master', "Master's", 'Masters', 'M.S.', 'M.S', 'MS', 'PhD', 'Ph.D.', "PhD's", 'MBA'] edu_lower = [s.lower() for s in edu]# lowercases edu_map = pandas.DataFrame({'raw':edu, 'lower':edu_lower})# create a dataframe edu_map['raw'] = ['BS', "BS", 'BS', "BS", 'BS', 'MS', "MS", 'MS', 'MS', 'MS', 'MS', 'PhD', 'PhD', "PhD", 'MBA'] # modify the mapping edu_dic = list(edu_map.set_index('lower').to_dict().values()).pop()# use the dataframe to create a dictionary # print(edu_dic)Preferred Majors
##### Major ##### major = ['Computer Science', 'Statistics', 'Mathematics', 'Math','Physics', 'Machine Learning','Economics','Software Engineering', 'Engineering', 'Information System', 'Quantitative Finance', 'Artificial Intelligence', 'Biostatistics', 'Bioinformatics', 'Quantitative'] major_lower = [s.lower() for s in major]# lowercases major_map = pandas.DataFrame({'raw':major, 'lower':major_lower})# create a dataframe major_map['raw'] = ['Computer Science', 'Statistics', 'Math', 'Math','Physics', 'Machine Learning','Economics','Software Engineering', 'Engineering', 'Information System', 'Quantitative Finance', 'Artificial Intelligence', 'Biostatistics', 'Bioinformatics', 'Quantitative']# modify the mapping major_dic = list(major_map.set_index('lower').to_dict().values()).pop()# use the dataframe to create a dictionary # print(major_dic)Interesting Keywords
##### Key Words ###### keywords = ['Web Analytics', 'Regression', 'Classification', 'User Experience', 'Big Data', 'Streaming Data', 'Real-Time', 'Real Time', 'Time Series'] keywords_lower = [s.lower() for s in keywords]# lowercases keywords_map = pandas.DataFrame({'raw':keywords, 'lower':keywords_lower})# create a dataframe keywords_map['raw'] = ['Web Analytics', 'Regression', 'Classification', 'User Experience', 'Big Data', 'Streaming Data', 'Real Time', 'Real Time', 'Time Series']# modify the mapping keywords_dic = list(keywords_map.set_index('lower').to_dict().values()).pop()# use the dataframe to create a dictionary # print(keywords_dic)
Use For Loop to scrape all the URLs and then pick out the interested terms if they are in the page texts.
Creat empty lists for storing features of all the jobs.
############################################## ##### FOR LOOP FOR SCRAPING EACH JOB URL ##### ############################################## # empty list to store details for all the jobs list_type = [] list_skill = [] list_text = [] list_edu = [] list_major = [] list_keywords = []For each loop, create empty lists for storing features of the \(i^{th}\) job.
for i in range(len(job_df_careerbuilder)): # empty list to store details for each job required_type= [] required_skills = [] required_edu = [] required_major = [] required_keywords = []Extract the all the meaningful texts from the URL.
The reason for thetry:andexcept:in the for loop is to avoid termination from the forbidden pages.try: # get the HTML code from the URL job_page = requests.get(job_df_careerbuilder.iloc[i, 5]) # Choose "lxml" as parser soup = bs4.BeautifulSoup(job_page.text, "lxml") # drop the chunks of 'script','style','head','title','[document]' for elem in soup.findAll(['script','style','head','title','[document]']): elem.extract() # get the lowercases of the texts texts = soup.getText(separator=' ').lower()Clean the texts data.
# cleaning the text data string = re.sub(r'[\n\r\t]', ' ', texts) # remove "\n", "\r", "\t" string = re.sub(r'\,', ' ', string) # remove "," string = re.sub('/', ' ', string) # remove "/" string = re.sub(r'\(', ' ', string) # remove "(" string = re.sub(r'\)', ' ', string) # remove ")" string = re.sub(' +',' ',string) # remove more than one space string = re.sub(r'r\s&\sd', ' ', string) # avoid picking 'r & d' string = re.sub(r'r&d', ' ', string) # avoid picking 'r&d' string = re.sub('\.\s+', ' ', string) # remove "." at the end of sentencesFor each feature, pick out all the interested terms and then save them in a list.
##### Job types ##### for typ in type_lower : if any(x in typ for x in ['+', '#', '.']): # make it possible to find out 'c++', 'c#', 'd3.js' without errors typp = re.escape(typ) else: typp = typ # search the string in a string result = re.search(r'(?:^|(?<=\s))' + typp + r'(?=\s|$)', string) if result: required_type.append(type_dic[typ]) list_type.append(required_type) ##### Skills ##### for sk in skills_lower : if any(x in sk for x in ['+', '#', '.']): skk = re.escape(sk) else: skk = sk result = re.search(r'(?:^|(?<=\s))' + skk + r'(?=\s|$)',string) if result: required_skills.append(skills_dic[sk]) list_skill.append(required_skills) ##### Education ##### for ed in edu_lower : if any(x in ed for x in ['+', '#', '.']): edd = re.escape(ed) else: edd = ed result = re.search(r'(?:^|(?<=\s))' + edd + r'(?=\s|$)', string) if result: required_edu.append(edu_dic[ed]) list_edu.append(required_edu) ##### Major ##### for maj in major_lower : if any(x in maj for x in ['+', '#', '.']): majj = re.escape(maj) else: majj = maj result = re.search(r'(?:^|(?<=\s))' + majj + r'(?=\s|$)', string) if result: required_major.append(major_dic[maj]) list_major.append(required_major) ##### Key Words ##### for key in keywords_lower : if any(x in key for x in ['+', '#', '.']): keyy = re.escape(key) else: keyy = key result = re.search(r'(?:^|(?<=\s))' + keyy + r'(?=\s|$)', string) if result: required_keywords.append(keywords_dic[key]) list_keywords.append(required_keywords) ##### All text ##### words = string.split(' ') # transform to a list job_text = set(words) - set(stop_words) # drop stop words list_text.append(list(job_text)) except: # to avoid Forbidden webpages list_type.append('Forbidden') list_skill.append('Forbidden') list_edu.append('Forbidden') list_major.append('Forbidden') list_keywords.append('Forbidden') list_text.append('Forbidden') #print(i) # for tracking purposeAdd all features to the original datafame and update the
.csvfiles.# Add new columns job_df_careerbuilder['job_type'] = list_type job_df_careerbuilder['job_skills'] = list_skill job_df_careerbuilder['job_edu'] = list_edu job_df_careerbuilder['job_major'] = list_major job_df_careerbuilder['job_keywords'] = list_keywords job_df_careerbuilder['job_text'] = list_text # reorder the columns cols=['from','date','job_id','job_title','job_company','job_location','job_link','job_type', 'job_skills', 'job_edu', 'job_major', 'job_keywords','job_text'] job_df_careerbuilder = job_df_careerbuilder[cols] # print the dimenstion of the dataframe print(job_df_careerbuilder.shape) # save the dataframe as a csv file # path = '/path/output/' + 'job_careerbuilder_' + now_str_name + '.csv' job_df_careerbuilder.to_csv(path)(26, 13)
- Difficulties!
Let me know if you have better ideas about how to solve the following problems.- Not easy to get the exact text data I want.
My desired text data for each job page is only the job description part. However, it is hard to use simple code to separate them from other chunks nicely. Because of this, my code may pick some terms which are not shown in the job description part and then lower my data quality. - Different people say different terms.
For example, in our case if we click on the link of the following jobs, we will found that the “CSS” is just the abbreviation of the company’s name and “GCP” seems not to mean “Google Cloud Platform” at all. If this situation happens a lot, my data quality will be lowered again..

- Not easy to get the exact text data I want.
- Part II is done, but the code can be more efficient and neat! Part III is on the way!
Now, we know how to generate an informative.csvfile for the searching results from Careerbuilder. Then, we can just do the same things on Indeed, Monster and Dice. Check out my Github repo - webscraping_example for the example code.
If you follow my example code for the above four job searching websites, you will find that the code is repetitive, the.csvfiles are seperated and it is time consuming when we have a lot of searching results. So, I am trying to create modules and packages, combine all the seperated.csvfiles, and then use parallel computing module,multiprocessing, to speed up the running time. All the details will be in my next post, How Web Scraping eases my job searching pain? - Part III : Make it More Efficient.